socket.recv
本文仅讨论阻塞socket的情况。在v2ex上看到了2个提问,socket.recv 完整接收数据、python socket 一个很简单的问题把我难住了.主要会有2个方面。怎么判断数据是否传输完成了进行下一步操作。recv什么时候返回数据,返回多少字节
从一个读取文件的例子开始说起
1 | with open('backup.py') as f: |
这个例子中read是一直有数据返回的,文件读取完成就会一直返回空字符,这样就能判断什么时候完成就停止循环进入下一步操作了。
可能有些人会应用到socket编程中,recv后得到字符串,判断字符串长度。当长度为0的时候就认为传输完成了。惊奇的是这样写大多数时候居然真的能正常使用。看起来没什么问题。下面是一个例子
1 | import socket, time |
上面这个例子请求迅雷下载链接获得数据,在网络正常的时候是没有什么问题的。最后的打印的wait_time大概30左右。这其实是数据传输完成到socket关闭的时间(因为服务端设置了Connection: Keep-Alive且为30秒)。从效率来说数据传输完成我们白白等待了30秒,其次更重要的是仅仅对方服务器执行关闭操作s.recv才会返回空。万一对方服务器没有写好一直不关闭连接怎么办(不要以为不关闭不可能,不信可以连一下z.cn试一试)。所以从tcp层面来判断数据传输完成是不可取的,这种需求需要在应用层完成。
拿应用最广泛的http协议来说。它有明显的传输完成标志。上面的程序改写一下(忽略异常处理,不对chunk进行处理)
1 | import socket, time, re |
根据http应用层协议当服务端返回内容的时候,获取Content-Length头部内容然后recv接收所有需要内容后主动关闭连接,这样就不需要等待服务器关闭连接了。
另外recv或许还有一个比较容易曲解的地方recv(maxsize)并不是阻塞到直到获取到maxsize长度后才返回。这个地方可以这样理解,把这个IO流当做一个盒子。当盒子里面没有内容的时候recv是阻塞的。某一时刻盒子里面放进了一些内容,不管放进了多少recv会读取最多maxsize内容返回。顺便说一下epoll中边缘触发(edge-triggered)和水平触发(level-triggered)的理解。边缘触发就是当这个盒子中放进数据的时候我通知你一下。水平触发就是当这个盒子中还有数据没有取出的时候我通知你一下。这样就造成了使用边缘触发当通知的时候必须处理完该IO流(试想一下如果你第上一个通知没有处理完,下一个通知的时候也可以处理,依次递推可能造成最后一个通知没有处理完,因为没有下一个通知哒,所以漏处理了一些IO流)
总结来说就是2个方面。1.recv(maxsize)一有数据就返回并不是积累到maxsize长度再返回。2.判断传输完成不是TCP层面做的事情,应该在应用层处理
其他的一些
keepalive
tcp层面的:是表示当没有tcp报文的时候发送tcp报文给对方。实际上TCP协议规范是只有2小时没有tcp交互才会关闭TCP连接的,可是现实中各种NAT设备并没有遵循该规范,毕竟和性能有关联,如果长时间没有tcp包交互那么可能会中断该TCP连接,此时就有了tcp层面的keepalive,当没有tcp包的时候会自动发送。你以为这样就完了,too naive!有的NAT设备会当tcp中长时间没有有效荷载的时候中断该连接。于是乎有的应用在应用层每隔一段时间发送一个echo数据这样子就能够避免这种情况了。下图设置了keepalive同时对socket设置超时的情况
1 | def set_keepalive_linux(sock, after_idle_sec=1, interval_sec=3, max_fails=5): |
下图是抓包结果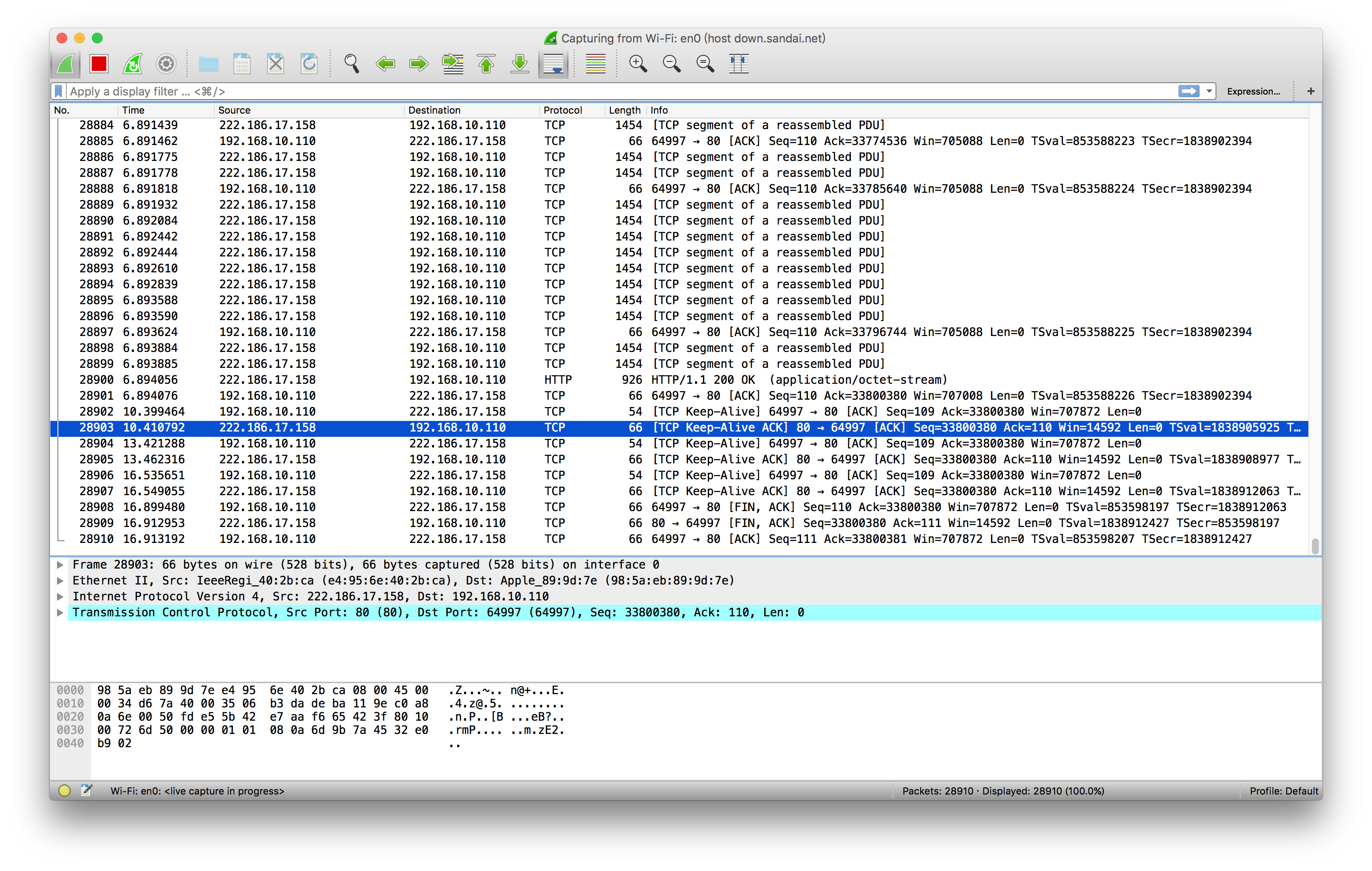
可以看到数据传输完成后每隔3秒钟发送了一个tcp包。由于同时设置了settimeout,十秒后没有tcp荷载,客户端断开了连接(注意settimeout设置为秒只对阻塞模式有效)
http层面的:这个就简单了,http1.0版本以前是请求→返回模式,请求一次就关闭了。因为tcp建立连接是挺耗时的,于是就有了一次数据来回就并不关闭下一个请求接着用。
超时检测
我觉得一个好的socket程序肯定会有超时机制和断线重连机制。上面的2个示例。测试中途断开网络再次重连接,会一直卡在recv阶段,对于一个死的TCP链接如果程序无法感知一直卡着绝对是无法接受的。如果是阻塞socket的超时我们只需要设置setttimeout就好了。配合应用层的echo也可以实现长连接。如果使用epoll这些那么settimeout就不行了,就需要自己维护状态检查~~~

 官方网站:
官方网站: