经常在本地电脑上使用pbcopy和pbpaste十分方便,但是ssh连接到远程机器后需要拷贝远程内容到本地相对就比较麻烦,以前总是需要采用ssh remote 'cat file' | pbcopy,搞多了就很烦,今天搜索了一下remote pbcopy之后发现了OSC52这个东西,用起来十分方便
本质就是输出一段特定格式的转义字符串,终端识别这个转移字符串得到原始内容,写入本机的粘贴板
远程主机
1 | sudo dd of=/usr/local/bin/osc52 <<'EOF' |
本机
Iterm2开启粘贴板访问权限
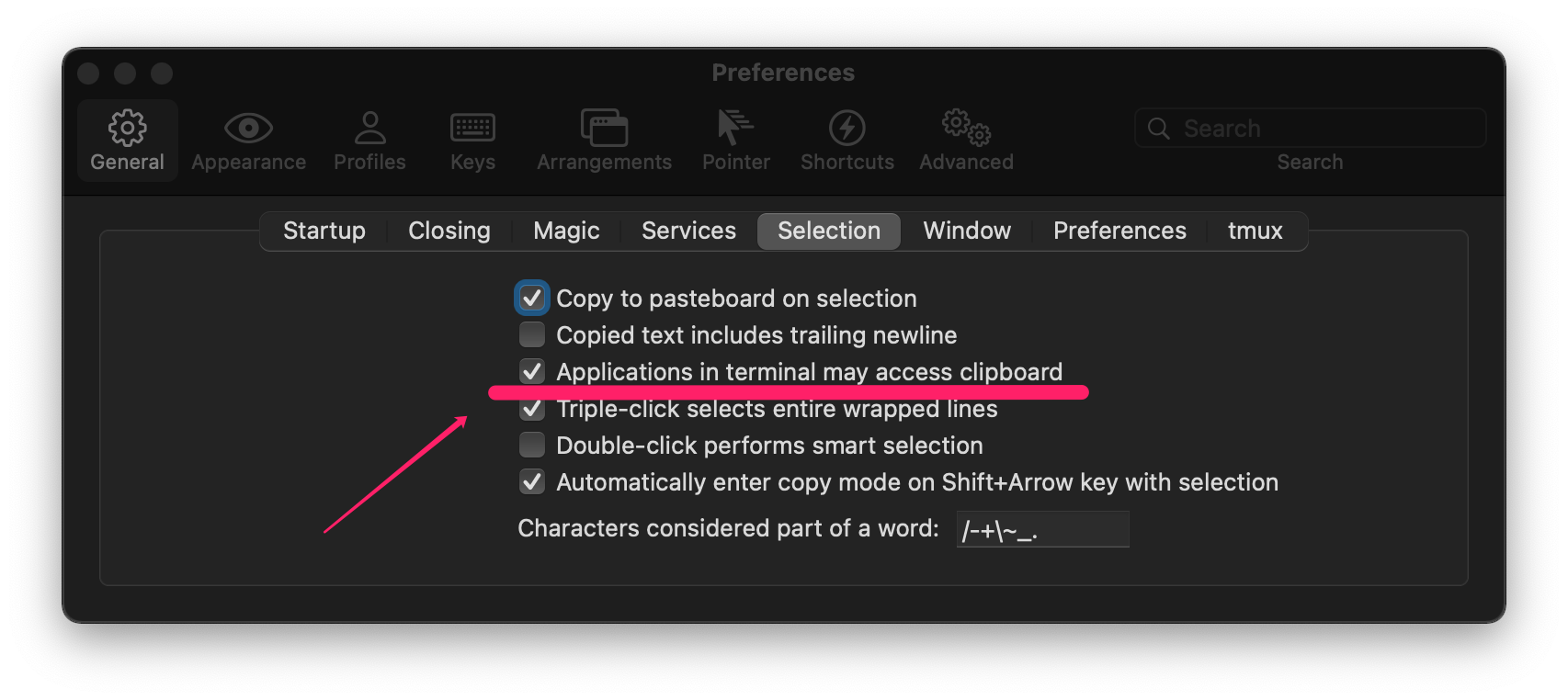
如果需要搭配tmux一起使用,需要在配置文件添加
1 | set -g set-clipboard on |
至此只需要在远程执行类似语句echo 123 | osc52 ,本机粘贴板就成功复制了
参考
[Remote Copy via OSC52](https://github-wiki-see.page/m/laktak/extrakto/wiki/Remote-Copy-via-OSC5

 官方网站:
官方网站: